From Pixels to Primitives

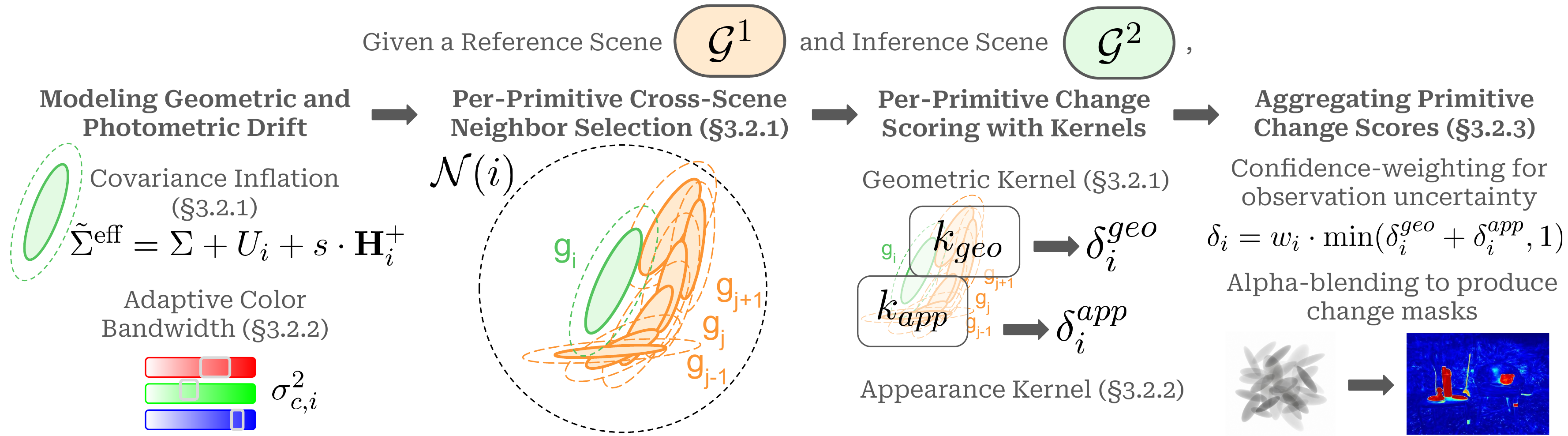
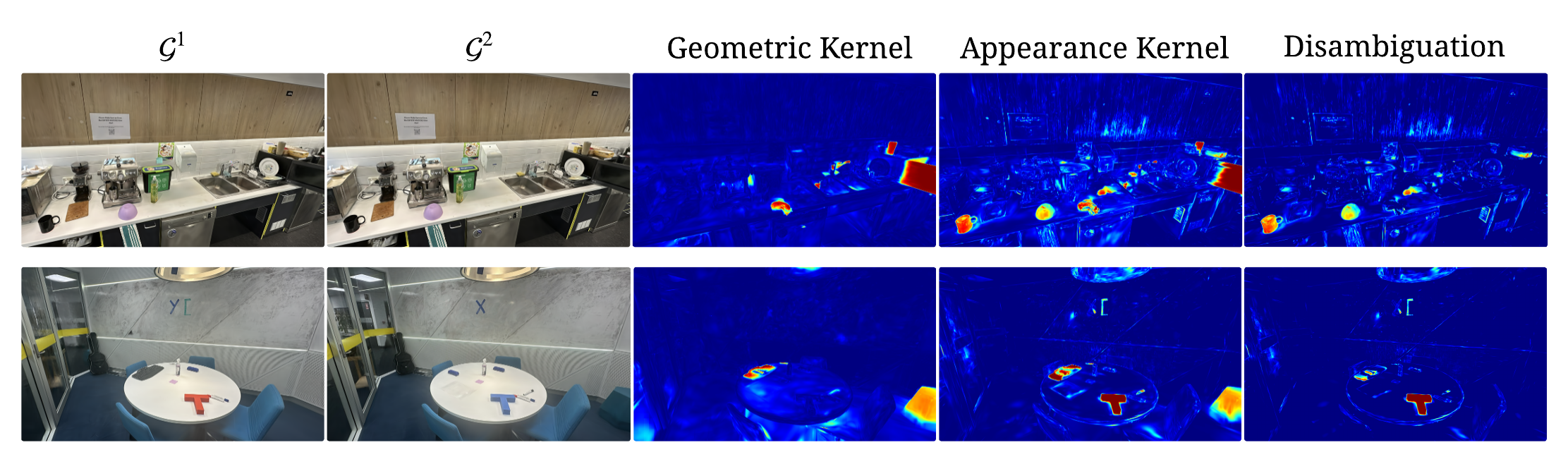
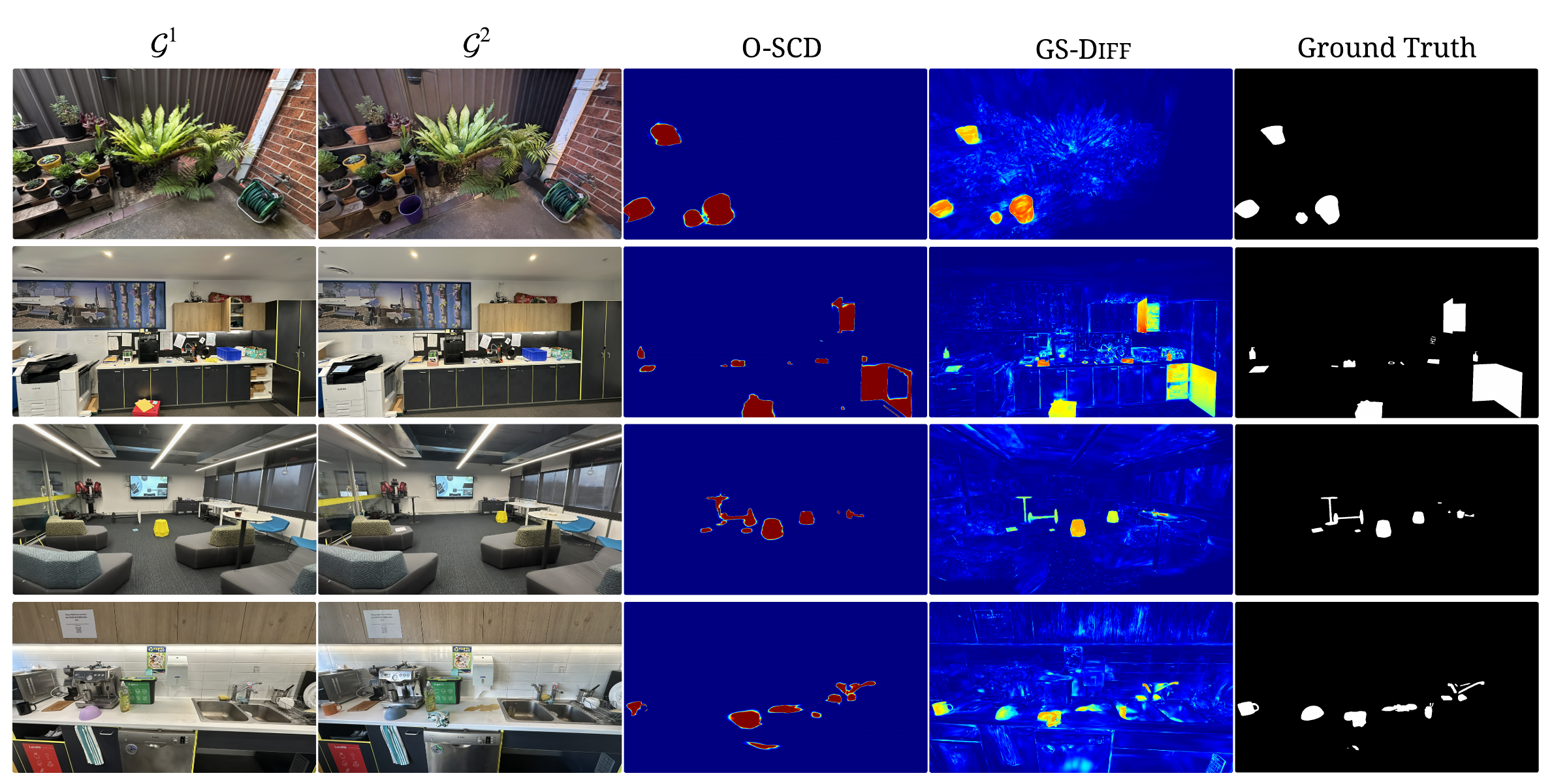
Figure 1. Prior multi-view SCD methods question pixels, comparing rendered viewpoint pairs in image space and learning to aggregate change evidence scattered across viewpoints (bottom). GS-Diff questions primitives, comparing two 3DGS reconstructions directly in primitive space (top). Multi-view consistency emerges by construction from the shared 3D representation, eliminating both per-view comparison and learned aggregation.